
What Does a COMMIT Do?-Redo and Undo-2
Before compiling the Java code, we need to set our CLASSPATH variable (this should all go on one line, no spaces, but doesn’t fit within the space on the page here):
$ export CLASSPATH=$CLASSPATH:$ORACLE_HOME/jdbc/lib/ojdbc8.jar:
$ORACLE_HOME/jlib/orai18n.jar
Also ensure that the Java executables are in your PATH variable (adjust this per yourORACLE_HOME):
$ export PATH=$PATH:/opt/oracle/product/19c/dbhome_1/jdk/bin
Next, we compile the Java code from the OS command line:
$ javac perftest.java
Now we’ll run this code repeatedly with different inputs and review the resulting TKPROF file. We’ll run with 100,000 row inserts—committing 1 row at a time, then 10, and so on. Here’s an example of running the first test from the OS command line:
$ java perftest 100000 1
The prior code does the inserts and also generates a trace file. You can locate the directory the trace file is in via this query:
SQL> select value from v$diag_info where name=’Diag Trace’;VALUE/opt/oracle/diag/rdbms/cdb/CDB/trace
Navigate to your trace directory and look for a recently generated trace file in that directory with the string of “insert into test”:
$ grep “insert into test” *.trc
CDB_ora_7660.trc:insert into test (id, code, descr, insert_user, insert_date)…
Process the file using the TKPROF utility (this creates a human-readable output file):
$ tkprof CDB_ora_7660.trc output.txt sys=no
After running the prior command, the file output.txt has the human-readable performance output of the insert test. The resulting TKPROF files produced the results in Table 9-1.
Table 9-1. Results from Inserting 100,000 Rows
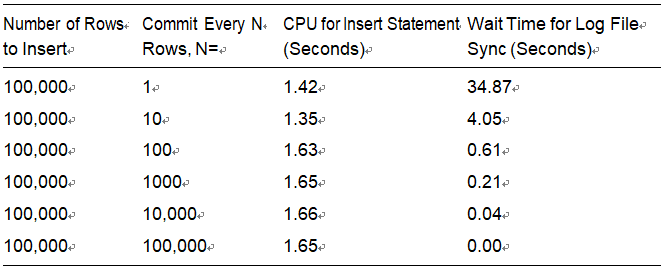
As you can see, the more often you commit, the longer you wait (your mileage will vary on this). And the amount of time you wait is more or less directly proportional to the number of times you commit. Remember, this is just a single-user scenario; with multiple users doing the same work, all committing too frequently, the numbers will go up rapidly.
We’ve heard the same story, time and time again, with similar situations. For example, we’ve seen how not using bind variables and performing hard parses often severely reduces concurrency due to library cache contention and excessive CPU utilization. Even when we switch to using bind variables, soft parsing too frequently— caused by closing cursors even though we are going to reuse them shortly—incurs massive overhead. We must perform operations only when we need to—a COMMIT is just another such operation. It is best to size our transactions based on business need, not based on misguided attempts to lessen resource usage on the database.
There are two factors contributing to the expense of the COMMIT in this example:
•\ We’ve obviously increased the round trips to and from the database. If we commit every record, we are generating that much more trafficback and forth. I didn’t even measure that, which would add to theoverall runtime.
•\ Every time we commit, we must wait for our redo to be written to disk. This will result in a “wait.” In this case, the wait is named“log file sync.”
So, we committed after every INSERT; we waited every time for a short period of time—and if you wait a little bit of time but you wait often, it all adds up. Fully 30 seconds of our runtime was spent waiting for a COMMIT to complete when we committed 100,000 times—in other words, waiting for LGWR to write the redo to disk. In stark contrast, when we committed once, we didn’t wait very long (not a measurable amount of time actually). This proves that a COMMIT is a fast operation; we expect the response time to be more or less flat, not a function of the amount of work we’ve done.