
Hypothetical Scenario: The Buffer Cache Fills Up Right Now-Redo and Undo
The situation is such that DBWn must make room and our modified blocks are to be flushed from the cache. In this case, DBWn will start by asking LGWR to flush the redo entries that protect these database blocks. Before DBWn can write any of the blocks that are changed to disk, LGWR must flush (to disk) the redo information related to these blocks.
This makes sense: if we were to flush the modified blocks for table T (but not the undo blocks associated with the modifications) without flushing the redo entries associated with the undo blocks, and the system failed, we would have a modified table T block with no undo information associated with it.
We need to flush the redo log buffers before writing these blocks out so that we can redo all of the changes necessary to get the SGA back into the state it is in right now, so that a rollback can take place.
This second scenario shows some of the foresight that has gone into all of this. The set of conditions described by “If we flushed table T blocks and did not flush the redo for the undo blocks and the system failed” is starting to get complex. It only gets more complex as we add users, more objects, concurrent processing, and so on.
At this point, we have the situation depicted in Figure 9-1. We have generated some modified table and index blocks. These have associated undo segment blocks, and all three types of blocks have generated redo to protect them.
The redo log buffer is flushed at least every three seconds, when it is one-third full or contains 1MB of buffered data, or whenever a COMMIT or ROLLBACK takes place. It is very possible that at some point during our processing, the redo log buffer will be flushed. In that case, the picture will look like Figure 9-2.
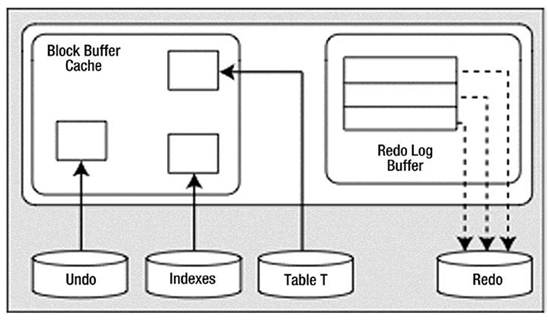
Figure 9-2. State of the system after a redo log buffer flush
That is, we’ll have modified blocks representing uncommitted changes in the buffer cache and redo for those uncommitted changes on disk. This is a very normal scenario that happens frequently.
The UPDATE will cause much of the same work as the INSERT to take place. This time, the amount of undo will be larger; we have some “before” images to save as a result of the UPDATE. Now we have the picture shown in Figure 9-3 (the dark rectangle in the redo log file represents the redo generated by the INSERT; the redo for the UPDATE is still in the SGA and has not yet been written to disk).
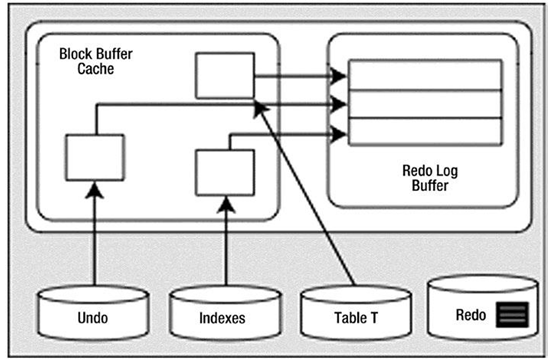
Figure 9-3. State of the system after the UPDATE
We have more new undo segment blocks in the block buffer cache. To undo the UPDATE, if necessary, we have modified database table and index blocks in the cache. We have also generated more redo log buffer entries. Let’s assume that our redo generated from the INSERT statement (discussed in the prior section) is on disk (in the redo log file) and redo generated from the UPDATE is in cache.